
Haseeb Shah
I am a Ph.D. student at the RLAI lab at University of Alberta advised by Prof. Martha White. My research focuses on foundational topics in Reinforcement Learning such as policy gradient algorithms, general value functions and recurrent learning as well as applying reinforcement learning to solve real-world problems in physical systems such as automating drinking water-treatment plants and controlling laser wakefield accelerators
Previously, I completed my M.Sc. with Prof. Martha White on Neural Network Pruning in the continual learning setting, worked at the LAVIS lab with Prof. Adrian Ulges on Knowledge Graph Completion and Semantic Code Search and at TUKL-SEECS lab with Prof. Faisal Shafait on Catastrophic Forgetting. Additionally, I have worked on Reinforcement Learning methods for real-time control of drinking water treatment plants at RL Core.
Education
University of Alberta
Ph.D. in Computer Science, September 2024-present
Supervisor: Martha White
University of Alberta
M.Sc. in Computer Science, 2021-2023
CGPA: 4.00/4.00
Supervisor: Martha White
Thesis: Greedy Pruning for Continually Adapting Networks
National University of Sciences and Technology
Bachlors of Engineering in Software Engineering, 2015-2019
Supervisor: Faisal Shafait
Thesis: An Open-World Extension for Knowledge Graph Completion Models
Publications
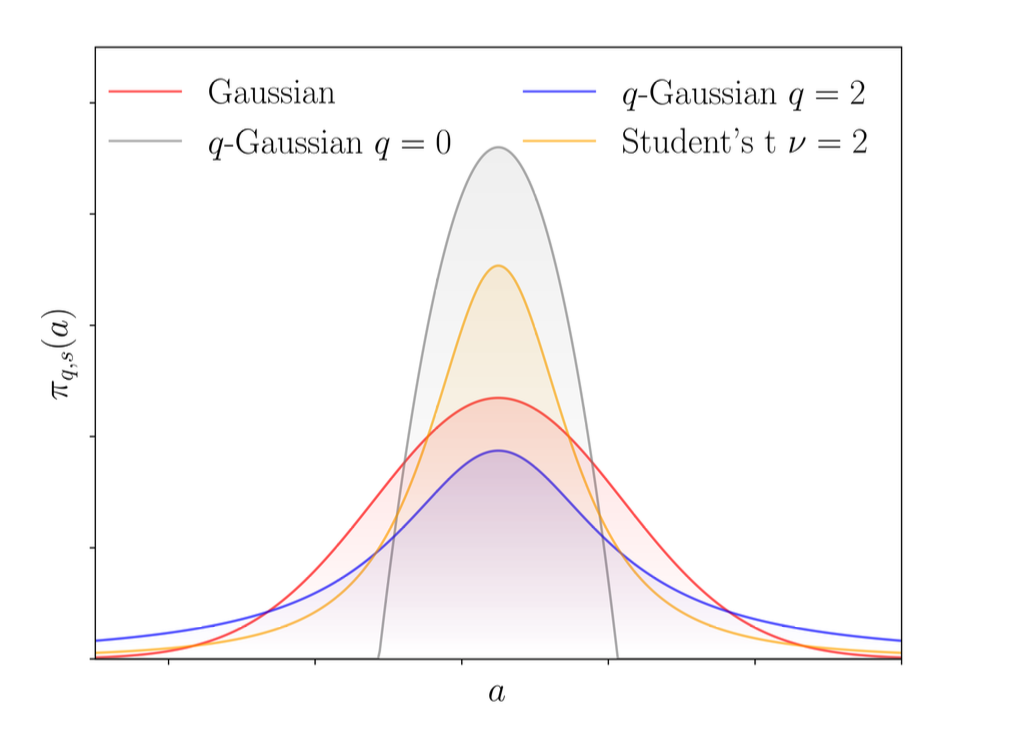
q-Exponential Family for Policy Optimization
L. Zhu*, H. Shah*, H. Wang*, M. White | *equal contribution
We explore the effectiveness of q-exponential policies in policy optimization methods, finding that heavy-tailed policies (q > 1) are generally more effective and can consistently outperform the Gaussian policy.
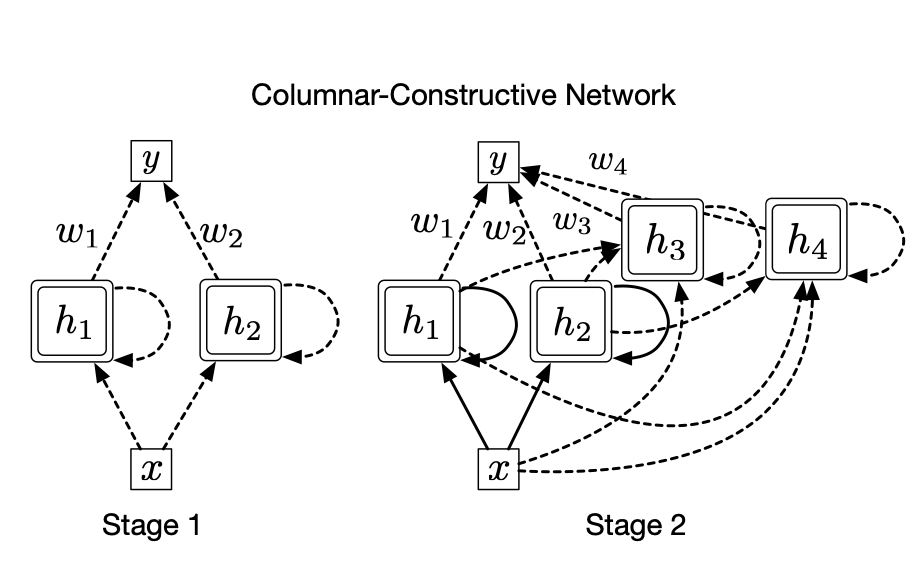
Scalable Real-Time Recurrent Learning Using Columnar-Constructive Networks
K. Javed, H. Shah, R. Sutton, M. White
We show that by either decomposing the network into independent modules or learning a recurrent network incrementally, we can make RTRL scale linearly with the number of parameters. Unlike prior scalable gradient estimation algorithms, our algorithms do not add noise or bias to the gradient estimate.
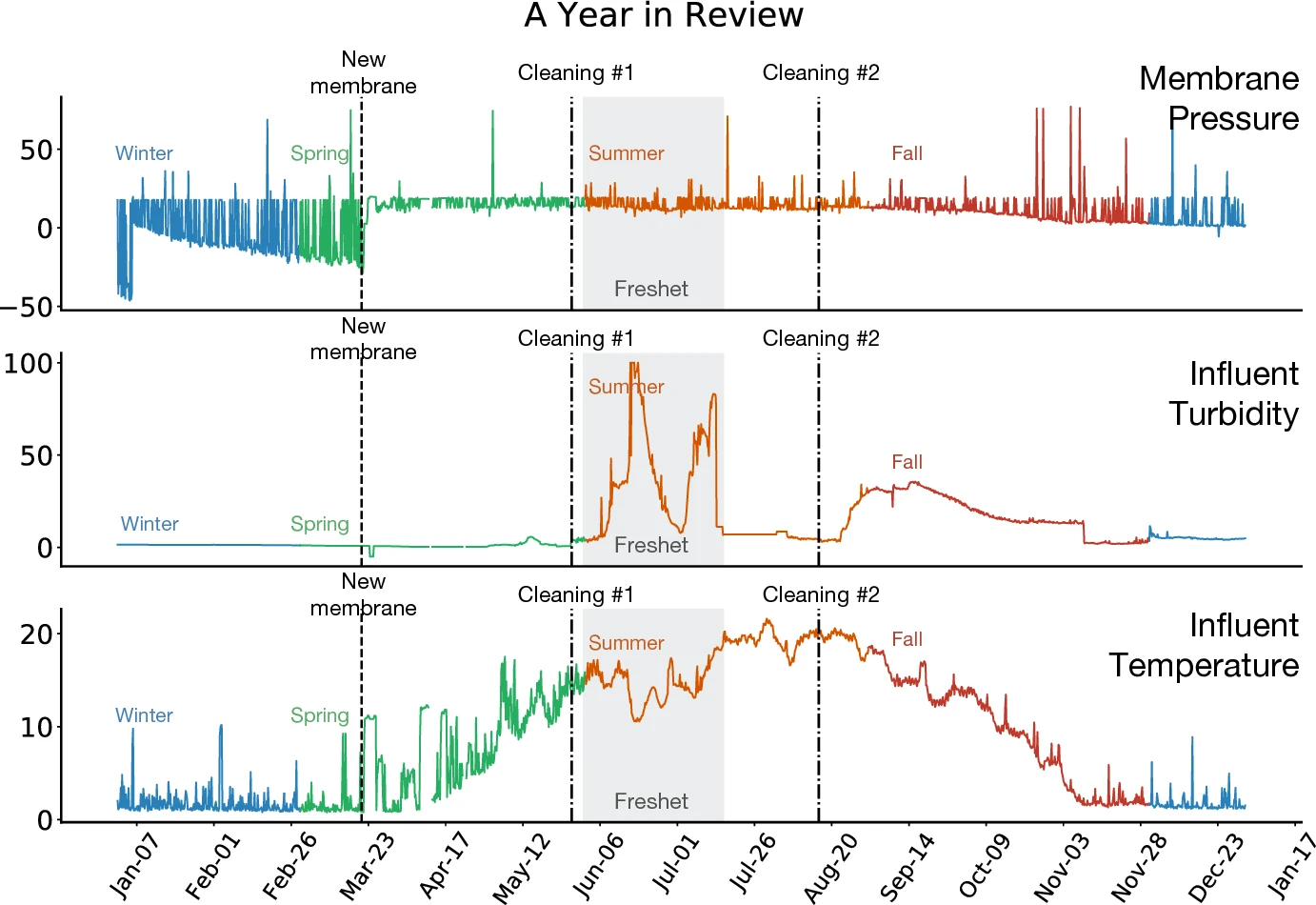
GVFs in the Real World: Making Predictions Online for Water Treatment
K. Janjua, H. Shah, M. White, E. Miahi, M. C. Machado, A. White
We propose a framework for making accurate predictions on a real world water treatment plant based on the General Value Functions. This work is one of the first to motivate the importance of adapting predictions in real-time, for non-stationary high-volume systems in the real world.
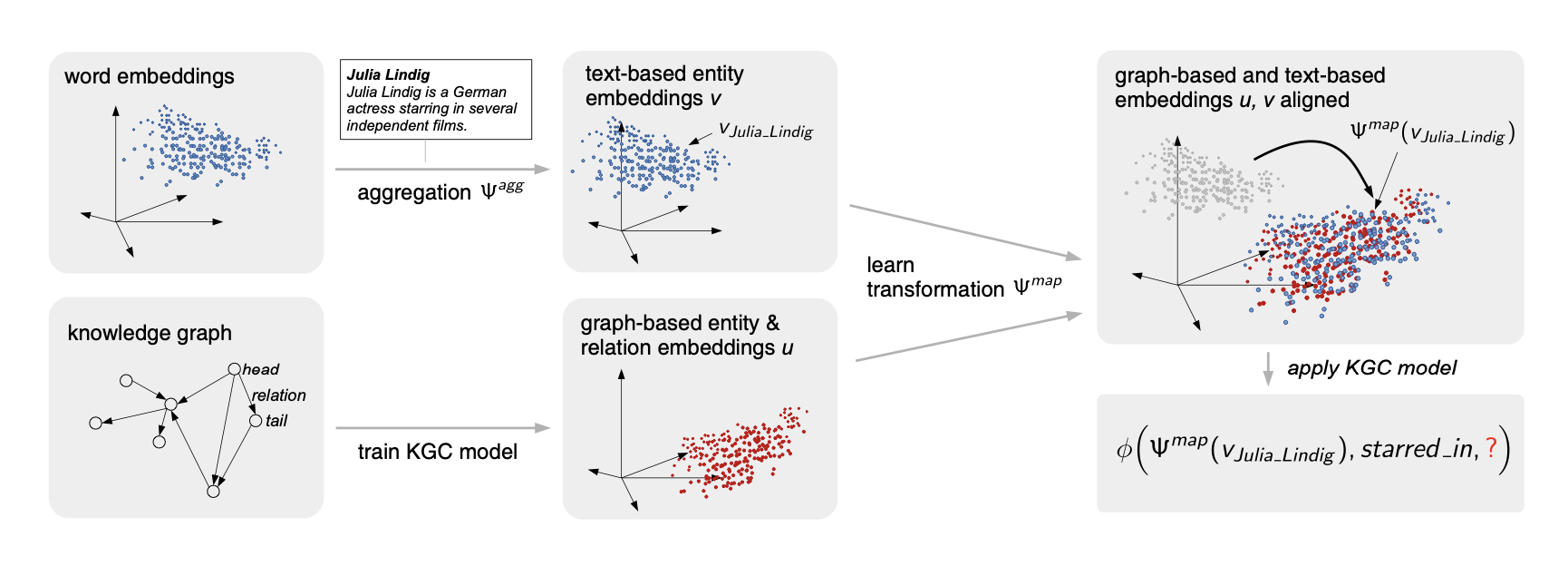
An Open-World Extension for Knowledge Graph Completion Models
H. Shah, J. Villmow, A. Ulges, U. Schwanecke, F. Shafait
We propose an extension that enables any existing Knowledge Graph Completion model to predict facts about the open-world entities. This approach is more robust, more portable and has better performance than the published state of the art on most datasets. We also released a new dataset that overcomes the shortcomings of previous ones.
Workshops & Preprints
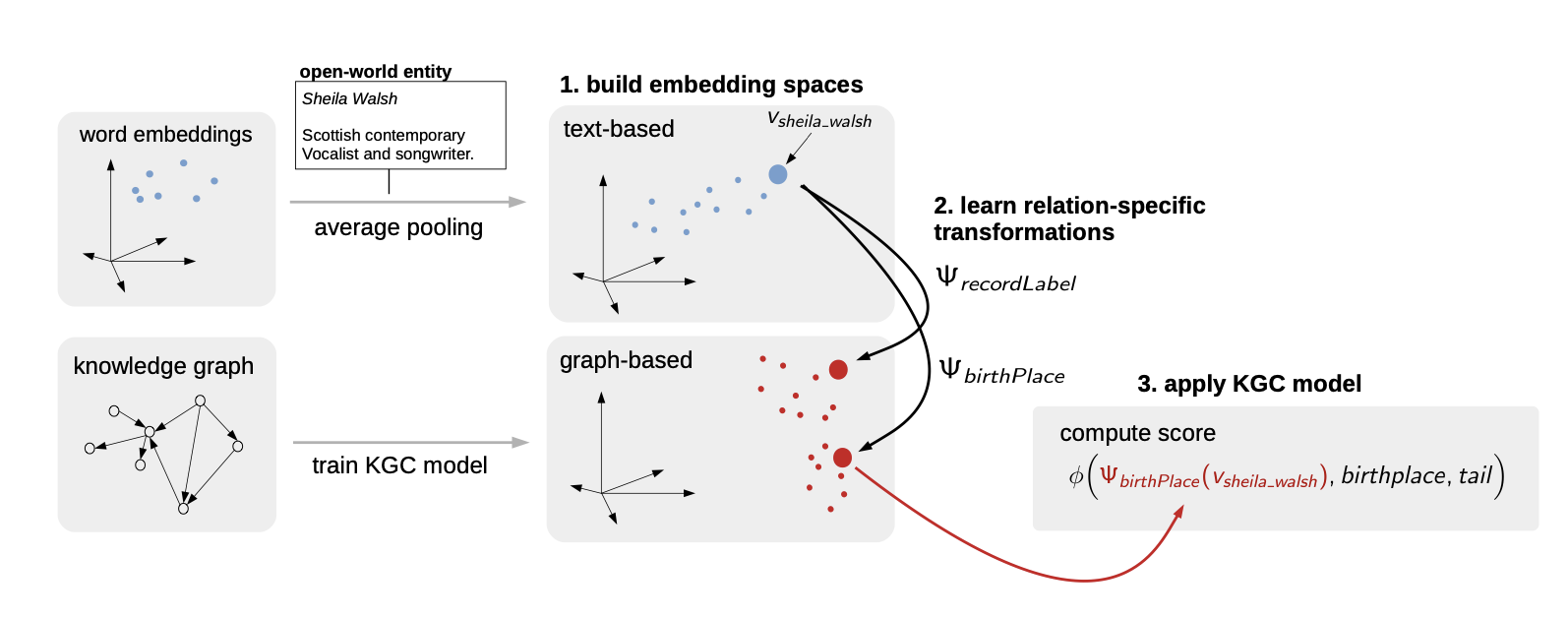
Relation Specific Transformations for Open World Knowledge Graph Completion
H. Shah, J. Villmow, A. Ulges
We introduced relation specific transformations to substantially improve the performance of Open World Knowledge Graph Completion models. We also proposed an approach for clustering of relations to reduce the training time and memory footprint.
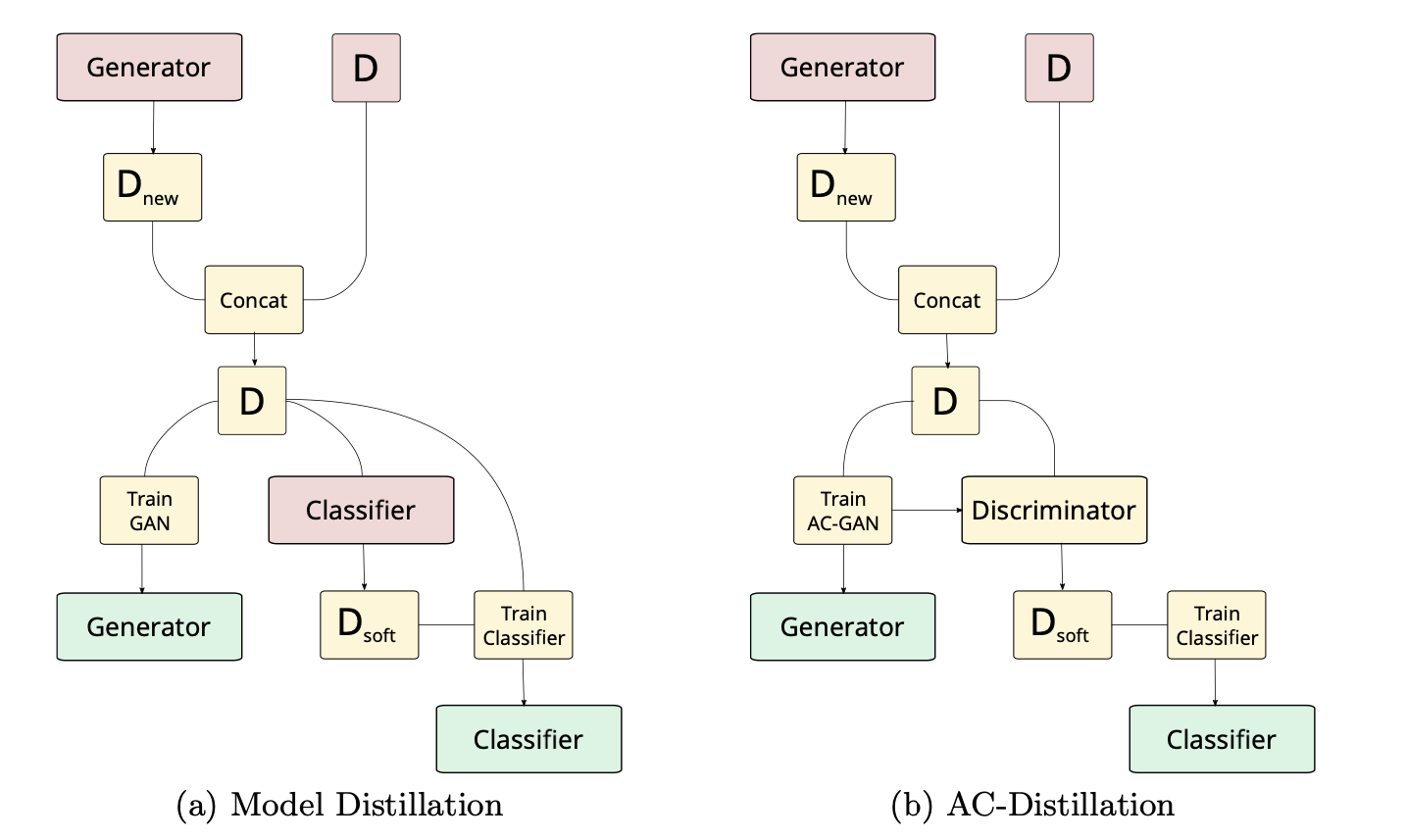
Distillation Techniques for Pseudo-rehearsal Based Incremental Learning
H. Shah, K. Javed, F. Shafait.
Standard neural networks suffer from catastrophic forgetting when they are trained on incrementally arriving stream of i.i.d. data. To combat this forgetting, one approach is to train GANs on previously arrived data and feed it to the network again. In this paper, we highlighted that this method is biased and proposed an approach to mitigate this bias and reduce the effect of catastrophic forgetting.
Public Talks
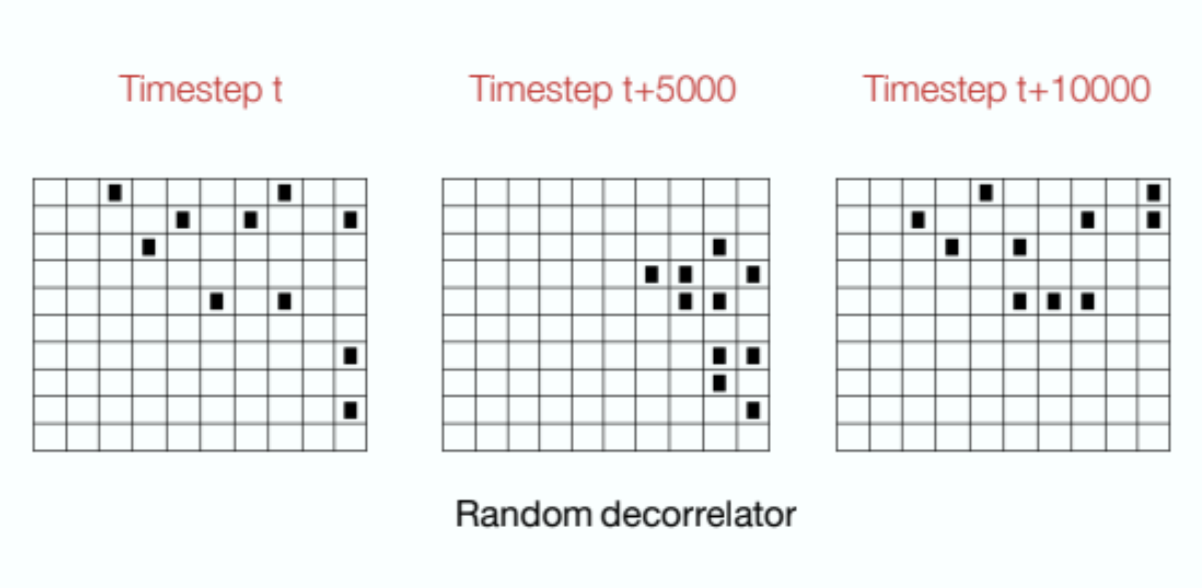
Online Feature Decorrelation
A significant proportion of the representations learned by the current generate & test methods consist of highly redundant features. This talk demonstrates how the feature ranking criteria utilized by these methods are highly ineffective in addressing this problem. In this talk, I present a new approach for decorrelating features in an online setting. I demonstrate that this decorrelator can effectively eliminate redundant features and produce a statistically significant performance improvement in the low-capacity function approximation setting.